MongoDB CDC with Debezium: Infrastructure & The Oplog Problem
Why Atlas shared tiers fail for CDC and how to configure a production-ready pipeline
The Promise of Event-Driven Architecture
CQRS (Command Query Responsibility Segregation) with event sourcing has become the gold standard for building scalable, eventually-consistent distributed systems. At its core, the pattern separates write operations from read operations. Since MongoDB uses an oplog internally, we can reuse it and selectively replicate data using Debezium as a CDC layer on authoritative write data, allowing downstream services to react to changes crossing service boundaries.
MongoDB paired with Kafka through Debezium's Change Data Capture (CDC) connector offers an elegant implementation of this pattern. Your application writes to MongoDB, Debezium captures every change from the oplog, and downstream consumers build read-optimized projections. In theory, it's beautiful. In practice, there's a critical infrastructure requirement that can make or break your entire architecture.
A note on schema discipline: It's incredibly important to have as close to strongly-typed schemas as possible in MongoDB. Without this, you'll run into data quality issues in your downstream pipeline. Use shared libraries and serialization tools to achieve consistency. Be aware that this enters data engineering territory, and you'll need to deal with all the challenges that come with it - schema evolution, backwards compatibility, and validation at service boundaries.
Real-World Architecture: Cross-Service Data Synchronization
Before diving into the technical details, let's look at a production implementation. Consider a search service that needs to index user data from a separate user service:
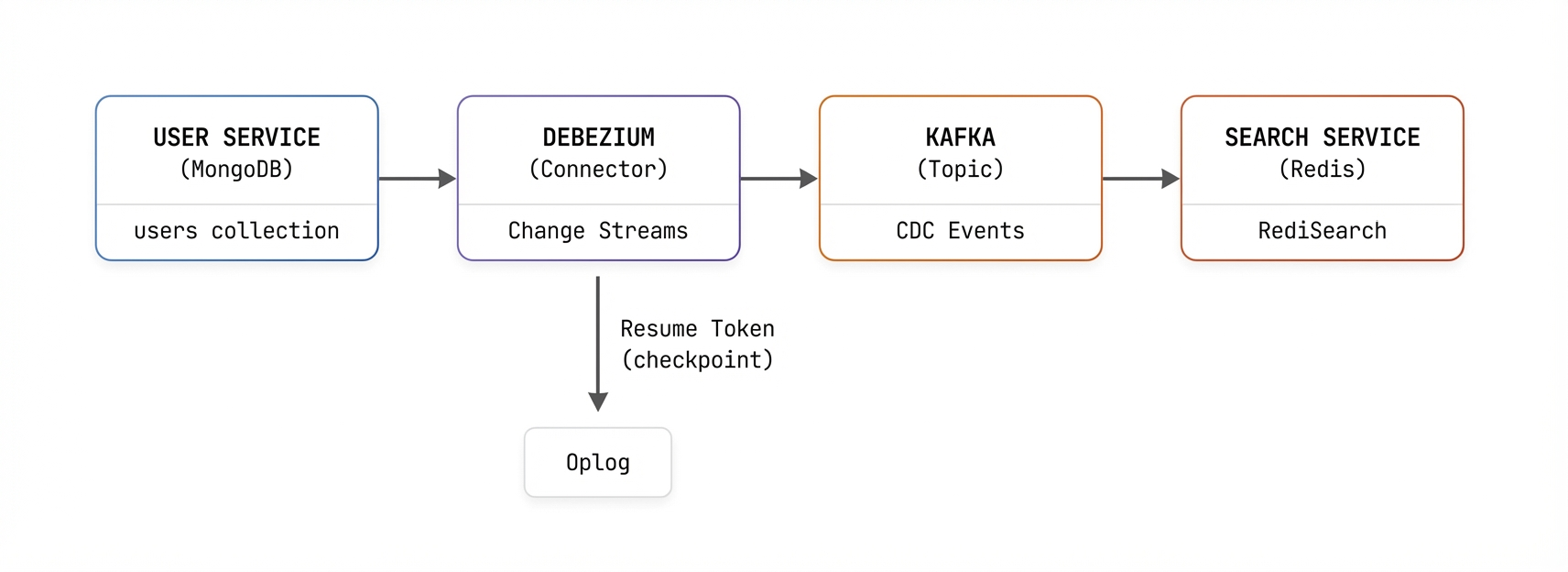
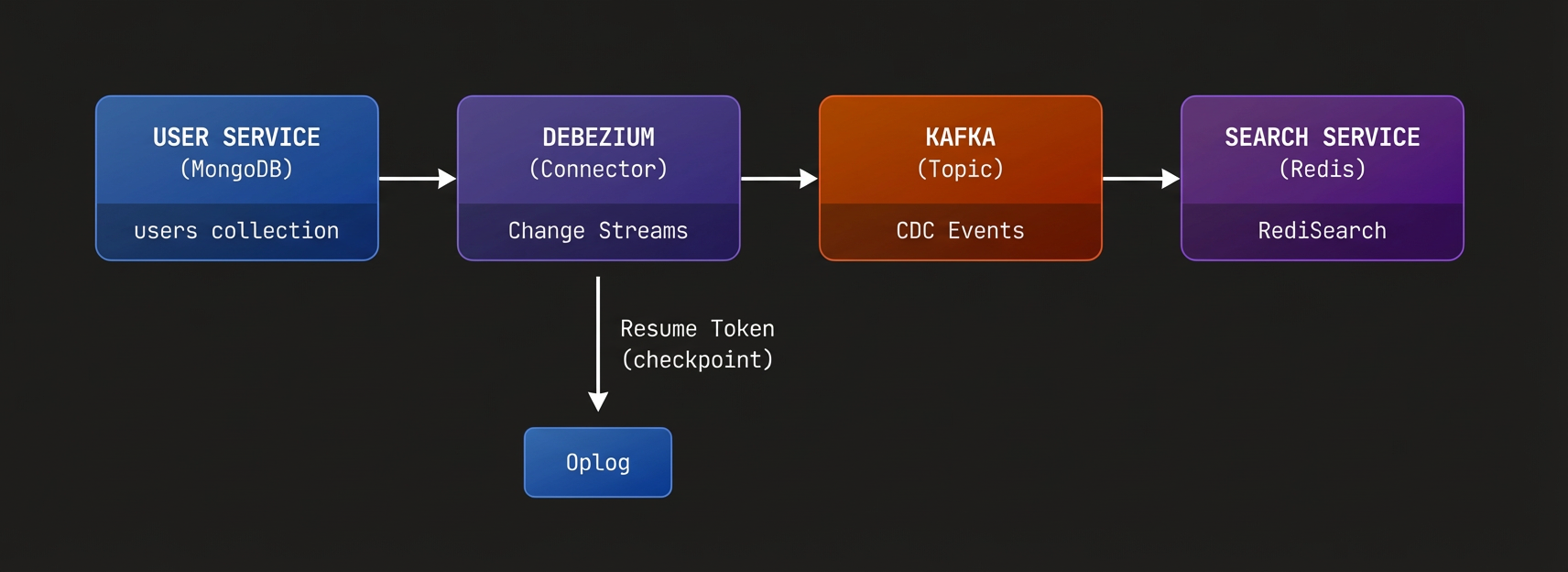
This pattern enables real-time search indexing without tight coupling in the temporal sense - the user service writes to MongoDB completely unaware of consumers, and Kafka provides natural backpressure handling. The search service maintains its Redis index independently, with sub-second latency from write to searchable. Note that in this simplest architecture example, you're still coupling data between services - the search service depends on the user service's data shape.
Production Debezium Connector Configuration
Here's a battle-tested Strimzi KafkaConnector configuration for MongoDB CDC:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: user-connector
namespace: debezium
labels:
strimzi.io/cluster: debezium-connect-cluster
spec:Show all 50 lines
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: user-connector
namespace: debezium
labels:
strimzi.io/cluster: debezium-connect-cluster
spec:
class: io.debezium.connector.mongodb.MongoDbConnector
tasksMax: 1
config:
# MongoDB Connection (Atlas M30+)
mongodb.connection.string: "${secrets:debezium/mongodb-credentials:connection-string}"
mongodb.ssl.enabled: "true"
# Topic Configuration
topic.prefix: "debezium-user-service"
database.include.list: "user-service"
collection.include.list: "user-service.users,user-service.debezium-signal"
# CRITICAL: Full document on updates (not just deltas)
capture.mode: "change_streams_update_full"
# Serialization
key.converter: "org.apache.kafka.connect.json.JsonConverter"
key.converter.schemas.enable: "true"
value.converter: "org.apache.kafka.connect.json.JsonConverter"
value.converter.schemas.enable: "true"
# Polling & Cursor Management
mongodb.poll.interval.ms: "30000"
cursor.max.await.time.ms: "30000"
# CRITICAL: Heartbeat keeps resume token fresh
heartbeat.interval.ms: "30000"
topic.heartbeat.prefix: "debezium-heartbeat"
# Snapshot Strategy
snapshot.mode: "when_needed"
snapshot.fetch.size: "5000"
# Error Handling with DLQ
errors.tolerance: "all"
errors.max.retries: "10"
errors.deadletterqueue.topic.name: "dlq-user-connector"
# Signal Channel for Recovery
signal.enabled.channels: "source"
signal.data.collection: "user-service.debezium-signal"
signal.poll.interval.ms: "15000"Configuration Deep Dive
| Setting | Value | Why It Matters |
|---|---|---|
capture.mode |
change_streams_update_full |
Emits complete document on updates, not just changed fields. Essential for building read models. |
heartbeat.interval.ms |
30000 |
Advances resume token even during write silence. Prevents token expiry on quiet collections. |
snapshot.mode |
when_needed |
Only re-snapshots if resume token is lost. Avoids unnecessary full table scans. |
signal.enabled.channels |
source |
Enables recovery signals via MongoDB collection. Operators can trigger snapshots without restart. |
errors.tolerance |
all |
Sends failed records to DLQ instead of crashing. Prevents poison pills from blocking pipeline. |
The Resume Token Problem
Here's where things get dangerous. MongoDB's oplog is a capped collection with a fixed size. Old entries are automatically purged when the oplog reaches capacity. The resume token is only valid as long as the corresponding oplog entry still exists.
Consider this scenario:
- Your Debezium connector is humming along, processing changes
- A brief network blip occurs, or the Strimzi operator restarts the connector pod
- The connector attempts to resume using its stored token
- MongoDB responds:
resume token not found in oplog - Your connector is now dead in the water
MongoServerError: cannot resume stream; the resume token was not found.Why Atlas Shared Tiers Are Dangerous for CDC
MongoDB Atlas cleverly manages shared database infrastructure to offer affordable free and low-cost tiers. Under the hood, your M0/M2/M5 cluster shares physical resources with many other tenants. This has a critical implication for CDC workloads: oplog churn.
Your change stream only receives events from your own database - MongoDB filters server-side, so you never see other tenants' data. However, the underlying oplog is shared physical infrastructure. All tenants' write activity contributes to oplog rotation, even though you can't see their events. Within your own database, you configure which collections to capture via collection.include.list.
The oplog window is determined by a simple relationship:
Where is the oplog size (bytes) and is the total rate at which oplog bytes are generated (bytes/sec).
On shared infrastructure, other tenants contribute to , which shrinks your window unpredictably. If the window drops to 36 seconds during a traffic spike from other tenants, any connector outage longer than ~36 seconds will break resume. You have no visibility into or control over this rate on shared tiers.
Even small blips in your change stream - a brief network hiccup, a connector restart, a Kubernetes pod reschedule - can cause you to lose your resume token. Once lost, Debezium cannot continue from where it left off.
The Recovery Nightmare
When the resume token is invalidated, your options are limited. The connector's snapshot.mode: when_needed setting will trigger a full re-snapshot, but this has consequences:
- Full snapshot duration: Re-reading millions of documents takes hours
- Duplicate events: Downstream consumers receive the entire dataset again
- Resource spike: MongoDB, Kafka, and consumers all experience load surge
For production systems requiring high availability, this is unacceptable.
Solutions
There are two paths to reliable CDC with MongoDB, depending on your infrastructure strategy:
Option 1: Atlas M30+ (Cloud-Hosted)
If you're using MongoDB Atlas, upgrade to M30 tier or above. These dedicated clusters provide extended oplog retention - Atlas guarantees a minimum oplog window regardless of write volume.
| Tier | Minimum Oplog Window | Use Case |
|---|---|---|
| M10/M20 | ~1 hour (best effort) | Development only |
| M30 | 24 hours guaranteed | Production CDC workloads |
| M40+ | 72+ hours | Mission-critical systems |
With M30+, even if your Debezium connector goes down for maintenance, experiences a crash, or the entire Kafka Connect cluster needs replacement, you have a 24-hour window to recover without losing your position in the change stream.
Option 2: Self-Hosted MongoDB
Self-hosting eliminates the shared oplog problem entirely. You control the entire oplog - there's no multi-tenant churn diluting your retention window. Configure --oplogSize based on your write throughput and desired retention period.
Self-hosting gives you predictable oplog behavior: your retention time equals your oplog size divided by your write rate, not the combined rate of hundreds of other tenants. For teams with existing Kubernetes infrastructure, this is often the more reliable choice for CDC workloads.
Architectural Recommendations
1. Budget for M30+ from Day One
The cost difference between M20 and M30 is insignificant compared to the operational cost of a single resume token incident. Don't start with shared tiers hoping to upgrade later.
2. Implement Heartbeat Events
The heartbeat.interval.ms: 30000 setting keeps the resume token advancing even during periods of no writes. Essential for collections with sporadic activity.
3. Use Dead Letter Queues
Configure errors.deadletterqueue.topic.name to catch failed records. This prevents poison pills from blocking your entire consumer group while preserving them for investigation.
4. Design for Idempotency
Even with all safeguards, design your consumers to handle duplicate events. Use upsert operations and include event IDs in your read models.
5. Monitor Consumer Lag
Track the gap between latest offset and committed offset. Alert if lag exceeds acceptable thresholds for your consistency requirements.
Conclusion
MongoDB + Kafka + Debezium is a powerful combination for CDC, but the resume token mechanism introduces a critical dependency on oplog retention. Atlas shared tiers (M0/M2/M5) suffer from oplog churn due to multi-tenant infrastructure, making CDC pipelines unreliable.
The solution is straightforward: use Atlas M30+ for guaranteed 24-hour retention, or self-host to eliminate multi-tenant churn entirely. Combined with proper heartbeat configuration and error handling, you get infrastructure that survives real-world failures.
In Part 2, we'll cover what to do once events land in Kafka - event handling patterns, building read models, and recovery strategies for your consumers.